Industrial AI Optimizer Data Pipeline
🏠 Home · 📚 Reading Notes · 📝 Articles · ℹ️ About
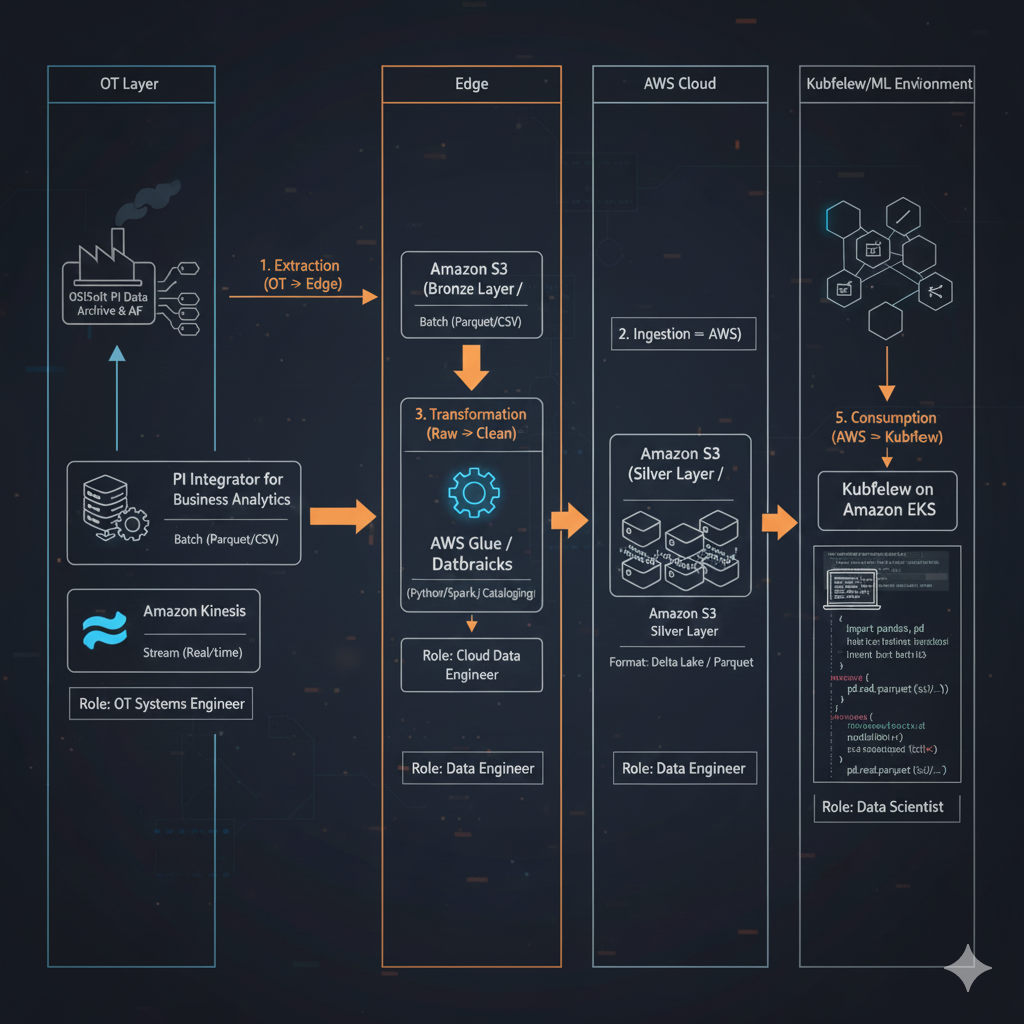
1. Extraction (OT Layer → Edge)
- The Source: OSIsoft PI Data Archive & Asset Framework (AF).
- The Tool: PI Integrator for Business Analytics.
- Why: It flattens the hierarchical AF data into a row-column format (like a spreadsheet) that cloud services can actually read. It removes the need for complex PI SDK coding.
- Alternative Tool: PI Web API + Custom Python Script (if you want to save money on licensing, but this increases maintenance).
- The Role: OT Systems Engineer. They configure the "View" in PI Integrator to select which tags and assets to publish.
2. Ingestion (Edge → AWS)
- The Target (AWS): Amazon S3 (Simple Storage Service) or Amazon Kinesis (if streaming real-time).
- The Method:
- Batch: PI Integrator writes Parquet/CSV files directly to an S3 Bucket (The "Landing Zone" or "Bronze Layer").
- Stream: PI Integrator pushes to Kinesis Data Streams.
- The Role: Cloud Data Engineer. They set up the S3 buckets, IAM roles, and security policies (The "Airlock" permissions) to allow the plant to write data in but not read data out.
3. Transformation (Raw → Clean)
- The Tool: AWS Glue (Serverless ETL) or Databricks (running on AWS).
- The Method:
- Cataloging: AWS Glue Crawler scans the S3 bucket to understand the schema (columns, types).
- Cleaning: An ETL job (Python/Spark) removes bad data (e.g., "I/O Timeout" values), handles missing timestamps, and converts units.
- The Role: Data Engineer. They write the PySpark scripts that turn raw sensor logs into a clean, queryable dataset.
4. Final Storage (The "Replica Store")
- The Location: Amazon S3 (The "Silver" or "Gold" Layer).
- The Format: Delta Lake or Parquet.
- Why: These formats are compressed and optimized for fast reading by machine learning models.
- The Role: Automated by the pipeline.
5. Consumption (AWS → Kubeflow)
- The Environment: Kubeflow running on Amazon EKS (Elastic Kubernetes Service).
- The Connection:
- The Data Scientist uses the AWS SDK for Python (Boto3) or a library like S3FS within their Kubeflow notebook.
- They do not query PI. They query the S3 buckets.
- The Role: Data Scientist. They write: df = pd.read_parquet('s3://my-plant-data-gold/reactor_data.parquet').